


Share
【機械学習モデル】評価方法とモデル評価の指標をくわしく解説
機械学習は様々な業界で革命をもたらしてきました。今後も機械学習のビジネスへの応用は、無限の可能性が広がっています。
AI開発やAIエンジニアの需要もますます高まっていくに違いありません。
この記事では、弊社Rabiloo(ラビロー)のAI開発プロジェクトの知見をもとに、
機械学習やディープラーニングのモデルを評価するさまざまな方法
課題に適した良いモデルの選定
についてRabiloo開発チームの知見をもとに解説したいと思います。
この記事では、以下の用語を取り上げます。
混同行列
正解率
適合率
再現率
特異率
F1スコア(F値)
ROC曲線
AUC
分散説明率
平均二乗誤差
機械学習におけるモデル評価方法
機械学習モデルを構築し、あるデータセットを学習させた後、次にすべきことは新しいデータセットでのモデルの性能を評価することです。
モデルの評価は、以下のような問題を解決するのに役立ちます。
モデルの学習は成功したか
モデルの成功度はどの程度か
いつ学習を中止すべきか
いつモデルを更新すべきか
以上の4つの質問に答えることで、そのモデルが本当に課題に適しているかどうかを判断できます。
良いモデルかどうかの評価は、通常、モデルが学習されていないデータセットに対して行われます。訓練データセットとテストデータセットの割合は70%と30%が一般的です。
モデルを評価する際に新しいデータを使用するのは、訓練セットをオーバーフィット(1つのモデルに過剰適合)させることを最小限に抑えるためです。モデルを評価すると同時に、モデルの最適な指標を見つけるために、モデルを訓練することが有効な場合もあります。
しかし、この評価を行うためにテストスイート(多数のテストケースを束ねたもの)を使用することはできません。あるいは、テストデータで最もよく機能するパラメータを選択する必要がありますが、それが最も包括的であるとは限りません。
機械学習モデル評価に適したデータセットに分割する
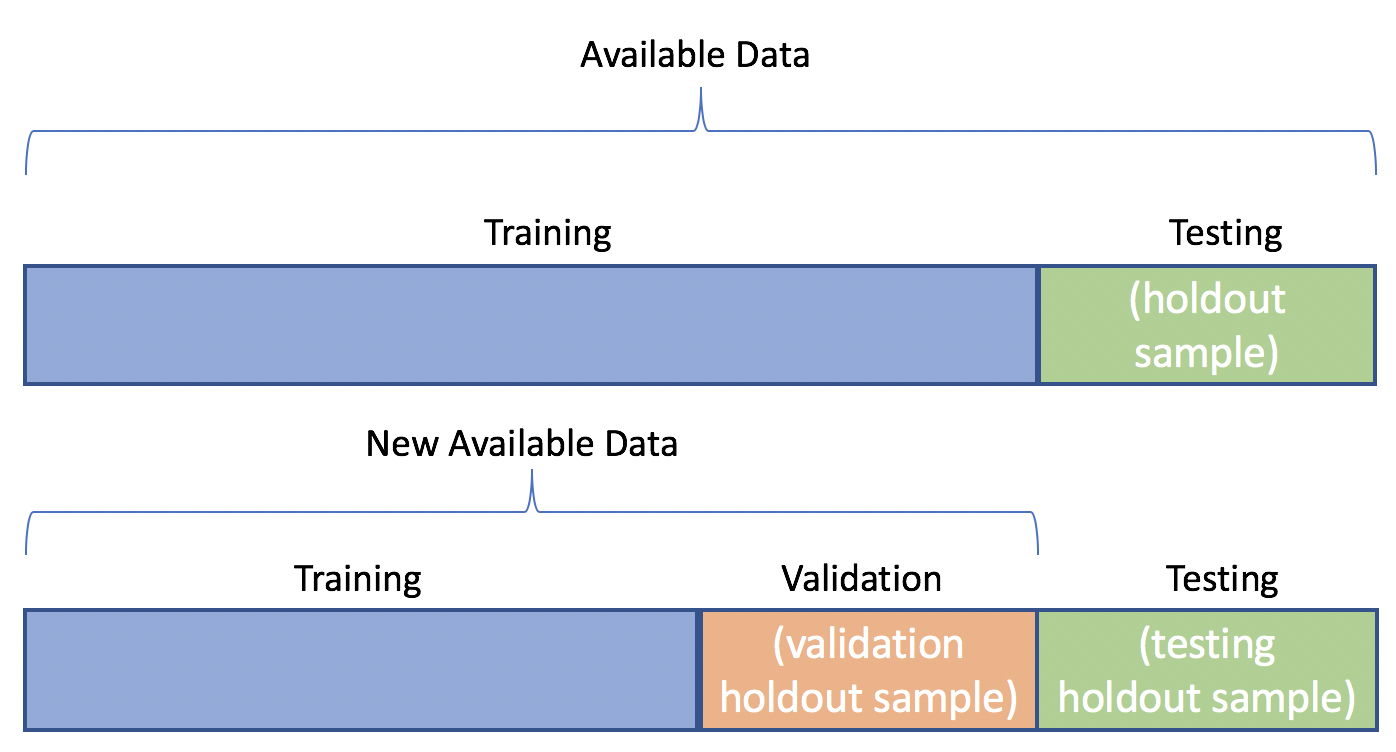
モデルを構築し、正規化しながら評価できるようにするために、評価用データセットと呼ばれるデータのサブセットを作成することができます。典型的なデータセットは、トレーニングセット60%、評価セット20%、テストセット20%の割合で構成されます。
データセットを小分けに分割する前にデータをシャッフルすると、データセットの乱れが大幅に改善されます。これにより、各サブセットが大きなデータセットの特性をより明確に表現することが可能になります。
さらに、データセットが大きい場合によく使用されるホールドアウト・リピートホールドアウト、不均衡なデータセットに使われる層化抽出法、交差検証、ブートストラップサンプリングなど、他のデータセット分割方法もあります。
機械学習モデルを評価する際の概念と指標
ここから、機械学習モデルを評価するための混合行列と回帰モデルの評価指標について考えます。
混合行列
分類問題を実行する場合、4つの予測が可能です。
真陽性(True Positive: TP):オブジェクトはPositiveクラスであり、モデルはオブジェクトをPositiveクラスに分類(正しい予測)
【イヌかどうか】 イヌ(正)→ イヌだ(正)偽陰性(False Negative: FN):オブジェクトはNegativeクラスにあり、モデルは物体をNegativeクラスに分類する(正しい予測)
【イヌかどうか】 ネコ(誤)→ イヌじゃない(正)真陰性(True Negative: TN):オブジェクトはNegativeクラスにあるが、モデルはPositiveクラスに分類した(第一種過誤)
【イヌかどうか】 ネコ(誤)→ イヌだ(誤)偽陽性(False Positive: FP):オブジェクトがPositiveクラスであるにもかかわらず、モデルがNegativeクラスに分類してしまう(第二種過誤)
【イヌかどうか】 イヌ(正)→ イヌじゃない(誤)
上記の情報を下記のように混合行列でまとめられます。

混合行列
モデルを評価するための指標は主に3つあります。
正解率(Accuracy)は、全データに対する予測の正答率として定義されます。正しい予測の数を全予測で割ることで簡単に計算できます。
適合率(Precision)とは、与えられたクラスに属すると予測したすべてのサンプルのうち、どのくらい正しく予測できたかの割合です。
再現率(Recall)とは、あるクラスに属すると予測されたサンプルのうち、実際にそのクラスに属したすべてのサンプルと比較した割合です。
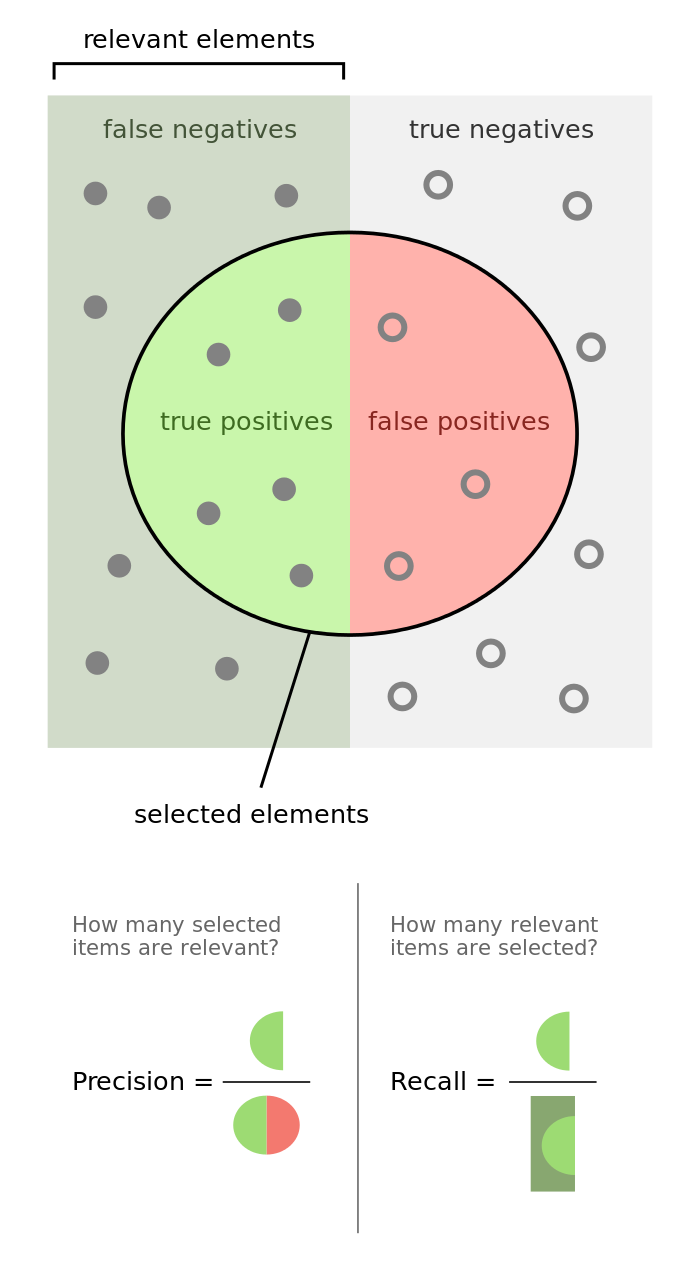
出典: https://en.wikipedia.org/wiki/Precision_and_recall
適合率と再現率は不均衡データの場合によく使われます。
ある人が病気を持っているかどうかを予測するアルゴリズムの開発を例に考えましょう。
ツールは、検査した人全員が病気にかかっていないという結果をはじき出しますが、実際は患者の1%がその病気にかかっていると仮定します。
それでもこのツールは、まだ99%の精度を保っていることになります。
しかし、だれがその病気にかかっているかはわかりません。つまり、このツールの有用性は0%です。
したがって患者に病気があるかどうかを正しく判断するにはモデルの適合率と再現率の両方を評価することが重要です。
適合率と再現率を組み合わせることができるように、F1スコア(F値)を使います。F1スコアは以下のように計算できます。
βパラメータを使用すると、適合率と再現率のトレードオフをコントロールすることができます。
β < 1 の場合は適合率をより重視します。
β > 1 の場合は再現率をより重視します。
β = 1 の場合は適合率と再現率の両方に焦点を当てます。
β = 1のとき、適合率と再現率の調和平均であるF1スコアが使われます。F1スコアは適合率と再現率の値がともに大きい場合に大きくなります。逆に、1つだけ小さい値があると、F1スコアも小さくなります。
分類問題では、分類アルゴリズムが入力データのあるスコアや確率を予測することが多くあります。これにより、分類モデルの精度が確認できるようになります。
確率やスコアを予測した後、それらの値をクラスのラベルに変換する必要があります。確率、スコアからラベルへの変換は「しきい値」によって決定されます。
ROC曲線は、モデルに対して適切なしきい値を選択するためのツールです。
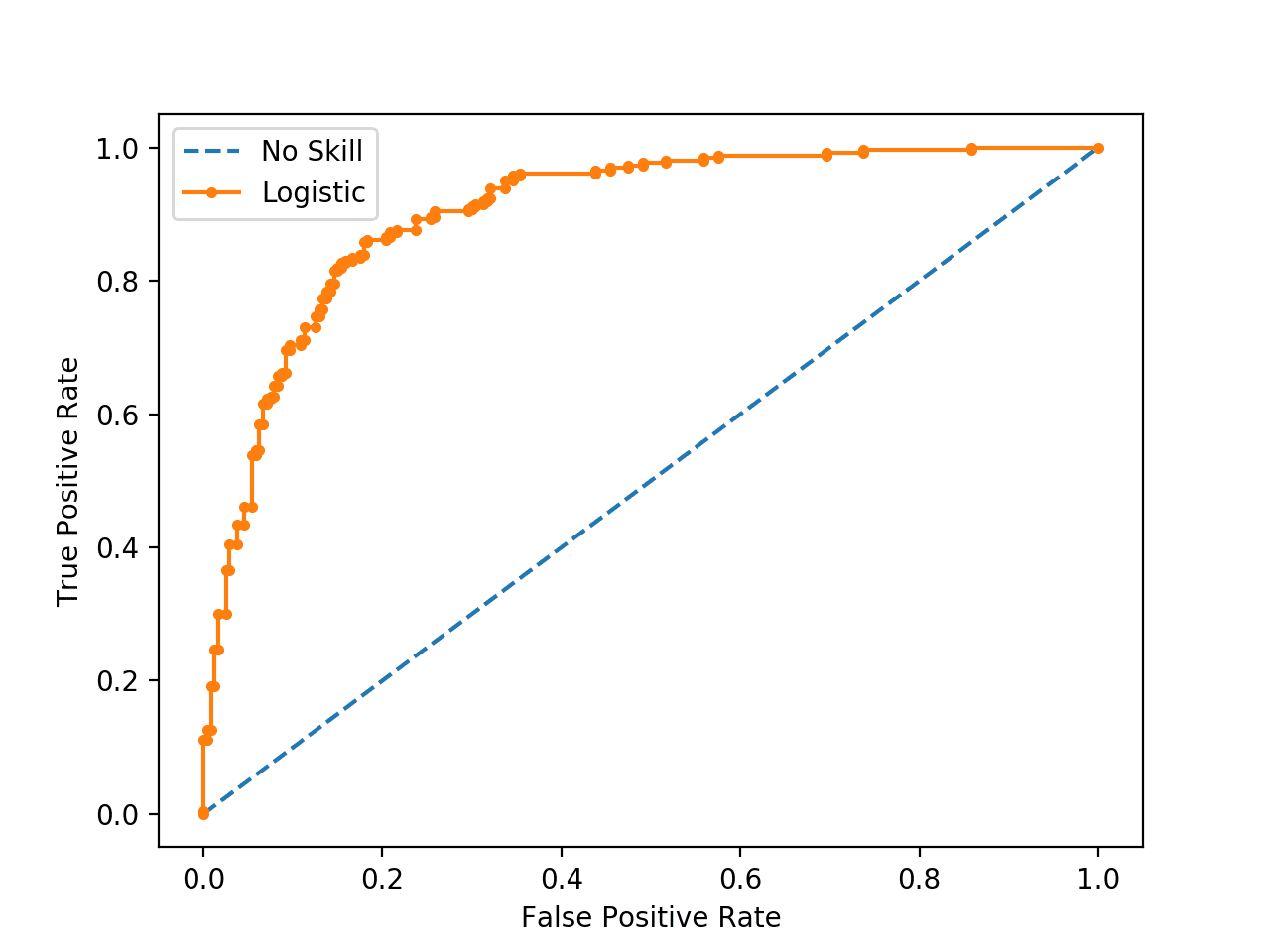
それぞれのしきい値について、ROC曲線上の値を求めます。
真陽性率(True Positive Rate、TPR)(または感度 sensitivity / 再現率 recall)はモデルの感度であり、陽性クラスにおいて予測がどれだけ正確であるかを示します。TPRは、正のクラスで正しく予測されたデータポイントの数と正のクラスでのデータポイントの数の商です。
偽陽性(False Positive Rate)とは第二種過誤の発生する確率です。
特異率(Specificity)とは、ネガティブクラスにおける予測の精度を示します。
オレンジ色の点は各しきい値を表し、縦軸はTPR値、横軸はFPR値です。課題によって、適切な閾値に対応する点を選択します。
AUC (Area Under the ROC curve)とはROC曲線下の領域で、モデルの分類性能を相互に評価するために使用されます。
モデルはAUCが大きいほど(ROC曲線が左上隅に近いほど)結果はより正確になります。
逆に、ROC曲線が45度の対角線に近いモデル(画像の青い破線)、つまりAUCが小さいほど結果が悪くなります。
AUCが高いほど、そのモデルはポジティブクラスとネガティブクラスの両方を正しく分類しやすくなります。
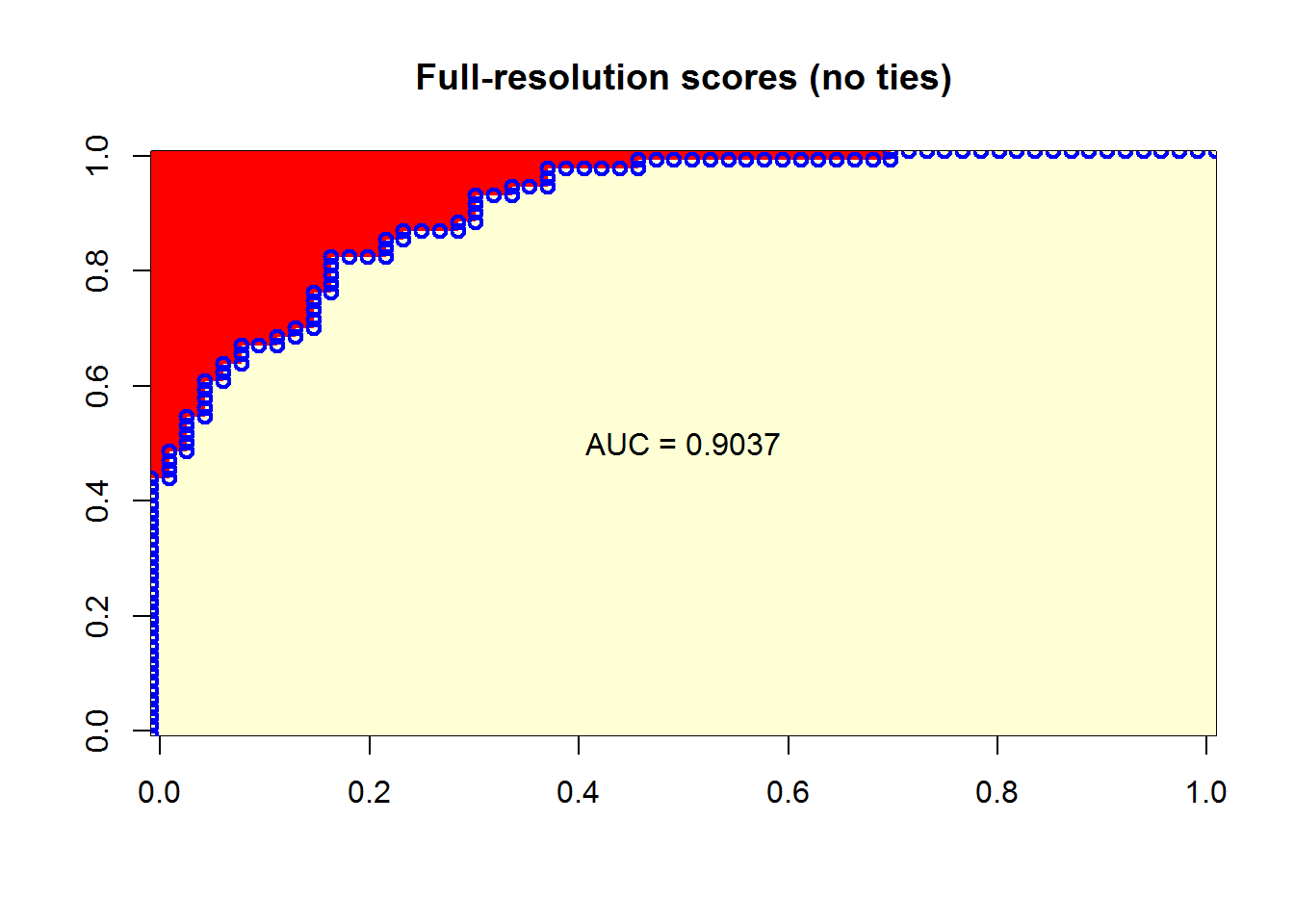
出典: https://blog.revolutionanalytics.com/2016/11/calculating-auc.html
回帰モデルの評価指標
回帰モデルの評価は離散クラスではなく、連続区間で予測しなければならないため、分類モデルの評価とはかなり異なります。
たとえば、ある家の価格を2億円と予測するモデルを構築し、それが2億1千万円で売れたとすると、それはよいモデルとみなされますが、分類モデルはその家が20億で売れるのかどうか、その家だけに関心を持ちます。このような違いがあるため、回帰モデルには他の評価指数が必要です。
分散説明率はその分散をモデルの誤差の分散と比較します。これは本質的に、モデルが説明できる元のデータ集合の変動の量を表します。データ全体のばらつきの何割くらいが説明可能かを表す指標です。
平均二乗誤差とは測定値と真値との差の二乗の平均値です。平均二乗誤差は、予測が高すぎるか低すぎるかを判断できず、予測が間違っているかを判断できます。
決定係数R2 (R2 coefficient)はモデルがその特徴に基づいて予測できる結果の分散の割合を表します。
まとめ
今回の記事では、モデル評価が重要な理由、データセットの分割と基本的なモデル評価指標の考え方についてご紹介しました。しかし、評価指標を選択することは、解決すべき課題によって大きく異なります。この記事を通じて機械学習モデル構築のプロセスの非常に大事なステップである評価指標の選択をより明確に理解していただければ幸いです。
AI開発、機械学習のビジネス活用など、先端技術プロジェクトの開発パートナーをお探しなら、ぜひRabiloo(ラビロー)をご検討ください。
当社は最新のAI技術と豊富な開発経験を活かし、お客様のビジネス課題を解決します。自然言語処理、画像認識、予測分析など、幅広いAI応用分野に対応し、プロトタイプ開発から本番環境への展開まで一貫してサポートいたします。
また、AIモデルの継続的な改善や運用保守も提供し、長期的な成功をお約束します。
どうぞお気軽にお問い合わせください。
関連記事:
Share