


Share
Nginxによるロードバランサーでサーバーの負荷分散をする
人気のオンラインショップや動画サイトに、たくさんの人が同時にアクセスすると、普通のシステムでは対応しきれず、サイトが遅くなったり、最悪の場合はダウンしてしまったりします。
サーバーのロードバランシング(負荷分散)は、大量のリクエストを受け付ける大規模なサーバーシステムにとって非常に重要で不可欠な技術です。ロードバランシングはWebサイトのパフォーマンスや品質、ユーザーエクスペリエンスに非常に大きな影響を与えます。
サーバーのロードバランシングはどのようにシステムの安定運用と、負荷に耐えるのにどのように役立つのでしょうか。
本記事では、オープンソースのWebサーバーソフトウェアであるNginxを使用したロードバランシングについて詳しく解説します。
Nginxとは?
Nginx(エンジンエックス)は、高性能で軽量なWebサーバーソフトウェアで、リバースプロキシサーバーとしても広く利用されています。その主な特徴は、大規模なWebサイトやアプリケーションにおける高負荷時のリクエスト処理能力にあります。Nginxは、2004年にIgor Sysoevによって開発され、以来、その高速性と効率性で多くのウェブサイトやアプリケーションに採用されています。
Nginxは非同期のイベント駆動アーキテクチャを採用しており、多数の同時接続を効率的に処理することが可能です。これにより、トラフィックが急増した場合でも、サーバーリソースを最適に利用し、システムの安定性とレスポンス時間を維持することができます。
また、Nginxはロードバランサーとしての機能も備えており、複数のバックエンドサーバー間でトラフィックを分散させることが可能です。これにより、システム全体の可用性と冗長性が向上し、単一障害点のリスクを軽減することができます。
さらに、静的コンテンツの高速配信、SSL/TLS終端、HTTP/2サポートなど、現代のWebインフラストラクチャに必要な機能を多数備えています。
わかりやすくいうと、Nginxは、Webサイトがたくさんのアクセスを受けたときに、スムーズに動くように手助けするソフトウェアです。大勢が同時にアクセスしても、Nginxはそのリクエストを効率よくさばいて、サーバーが落ちたり遅くなったりしないようサポートします。つまり、インターネット上の「交通整理係」のような役割を果たします。
これらの特性により、Nginxは大規模なEコマースサイト、ソーシャルメディアプラットフォーム、コンテンツデリバリーネットワークなど、高トラフィックを扱うWebサービスにおいて不可欠なコンポーネントとなっています。
Nginxの主な特徴:
高性能と低リソース消費
柔軟な設定
静的コンテンツの高速配信
効率的なリバースプロキシ機能
ロードバランシング機能
ロードバランシング(負荷分散)が必要になる背景
従来のシステムでは、ユーザーからのすべてのリクエストを1台のサーバーで処理していました。しかし、トラフィックが増加すると、以下の問題が発生します:
サーバーへの過大な負荷
レスポンスの遅延
サーバーのダウンタイムリスクの増加
これらの問題を解決するために、複数のサーバーを使用し、負荷を分散させる「ロードバランシング」が必要となります。
サーバーの負荷容量を増やす方法
サーバーの負荷容量を増やすには、2つの一般的な方法があります。
RAMやCPUなどのハードウェア構成の改善やアップグレード(垂直方向の拡張)
負荷がかかるサーバーの数を増やす(水平方向の拡張)
それぞれの方法には独自の効果と目的があり、最高の効率を達成するには両方の方法を組み合わせることもできます。
とりわけサーバーの増設は必須です。
負荷容量を満たすだけでなく、システムの継続的な稼働を確保することができます。1台のサーバーがダウンしても、他のサーバーが稼働し引き継ぐことができます。
しかし、サーバーを増やすと、サーバーのリソースの効率的な調整と管理に問題が生じます。
この問題を解決するのが、サーバーのロードバランシングです。
ロードバランサーとは?
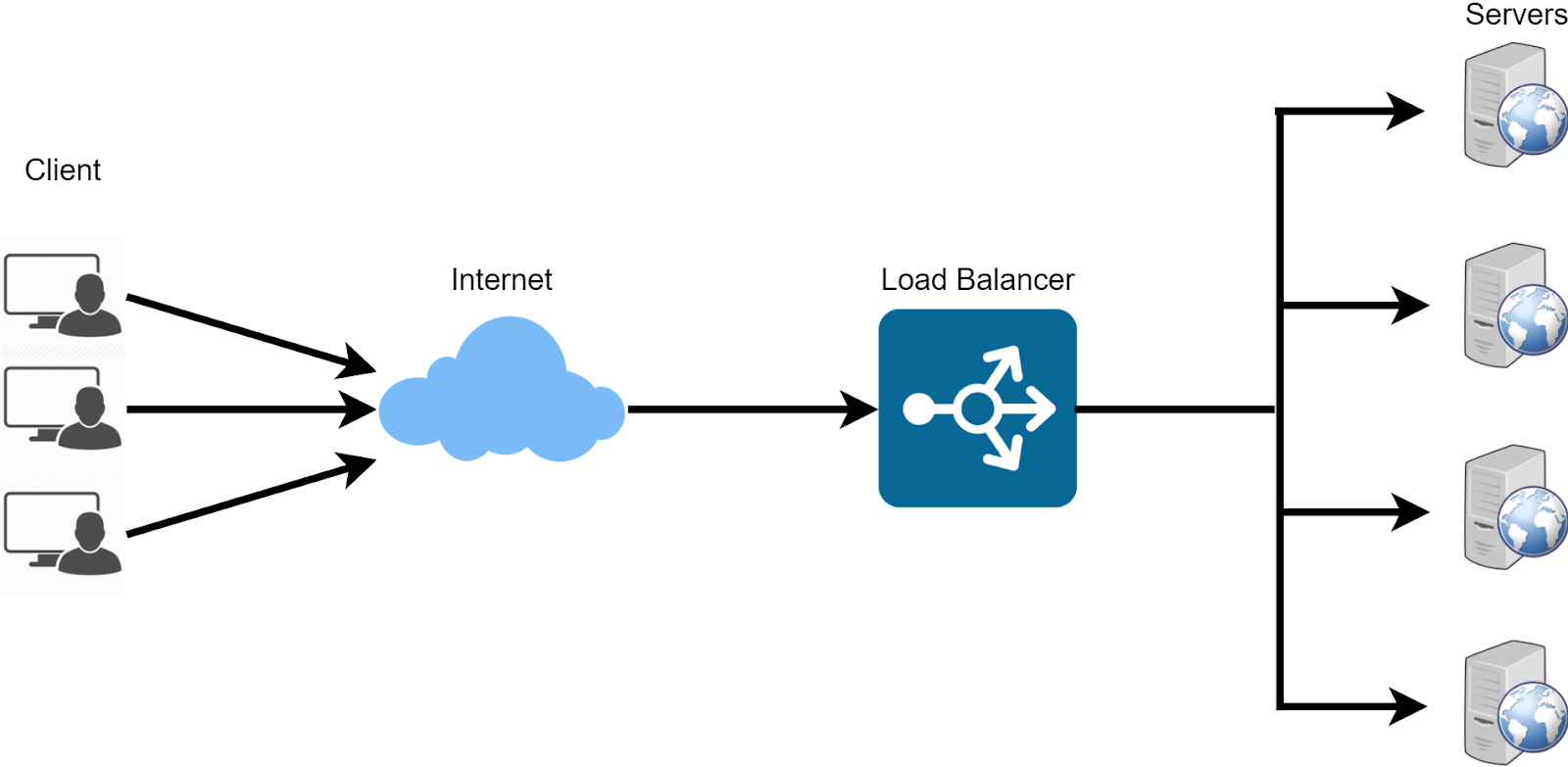
例えば、1台のサーバーでWebを管理している場合、同時にアクセスするユーザーが多すぎると、サーバーは非常に多くのリクエストに対応しなければなりません。
そのため、サーバーの過負荷、処理の困難、Webサイトのパフォーマンス低下、レスポンスの遅れ、さらにはサーバーのダウンが発生します。
この問題に対処するためには、サーバーに手を加える必要があります。
ただし、Webサイトが同じ管理下にある複数のサーバーを持つ場合、ロードバランシングと呼ばれる効果的な方法で解決することができます。
ロードバランシングとは、サーバープールやサーバーファームとも呼ばれる、サーバー群に対するトラフィック(リクエスト)を効率的かつ論理的に調整することです。
ロードバランシングの目的は、サーバーリソースの効率的な使用です。
リクエストの負荷が高いサーバーへの負担を減らし、アイドル状態のサーバーへのリクエストを調整することによって負荷を分散します。
このように、外部からのトラフィック(負荷)を複数のサーバーに平等に分散する装置のことを、ロードバランサーといいます。
ロードバランサーはリクエストの負荷が高いサーバーへの負担を減らし、アイドル状態のサーバーへのリクエストを調整することによってバランスを取ります。
ロードバランサーの役割
ロードバランサーは、サーバーとクライアントのルーティングの前で「交通警察」の役割を果たします。
「トラフィック渋滞」を起こすことなく、最適なスピードとパフォーマンスで各サーバーにストリームする
大量のリクエストがある場合に、過負荷のサーバーやアイドル状態のサーバーがないようにする。1台のサーバーがダウンした場合、ロードバランサーは他のサーバーにリダイレクトする
まとめると、ロードバランサーは主に以下のような機能を果たすことになります。
オンライン中のサーバーにのみリクエストを送ることにより、可用性と信頼性を確保する
クライアントのリクエストを複数のサーバーに効率よく分散させる
複数のサーバーを簡単かつ柔軟に縮小・拡張できる
ロードバランサーがネットワークに不可欠な理由
サーバーの数が多すぎると、サーバーのリソースを効率的に管理することが難しくなり、各サーバーの運用に関わる問題が発生します。
そのためには、高い技術力、時間とコストが必要です。
そこで上記のようなサーバー管理の問題を解決するために、サーバーのパフォーマンスを最適化するロードバランサーが誕生しました。
ロードバランサがネットワークに不可欠であるもうひとつの理由は、安定かつ継続的な運用ができ、信頼性を満たし、ビジネスの能力を発揮できるという点です。
ビジネスにおいてサーバーのダウンは許されない
従来のように、1台のサーバーだけでシステムを運用していた場合、そのサーバーがダウンすると、システムがエンドユーザーのニーズに応えられなくなります。
その結果、顧客のサービスが中断され、カスタマーエクスペリエンスを損ない、クレームを受けることになります。同時に、ユーザーからの信頼を大きく失い、電子商取引サイトや銀行システム、電子決済システムなどに甚大な影響を及ぼす可能性があります
そのため、企業は複数のサーバーを同時に使用する必要があり、ロードバランサーによって最高のパフォーマンスとスムーズな運用を実現します。
サーバーが100%落ちずに稼働することは保証されません。緊急時は、他のサーバーを利用して引き継ぎを行い、サーバーにかかる圧力を即座に分散させることを考えなければなりません。
このように、ロードバランサーを備えた複数のサーバーを利用することで、中断せずにビジネスを継続することができます。さらに、サーバーの過負荷状況を最小化し、エンドユーザーの顧客体験を向上させることができます。
Nginxによるロードバランシング
Nginxは、効率的なロードバランサーとして機能し、以下の利点を提供します:
トラフィックの均等分散
サーバーの可用性と信頼性の向上
システムの柔軟な拡張性
Nginxの代表的な導入例をいくつか紹介します。
Wordpressなど、WebアプリケーションのWebサーバ
HTTP、UDP 、TCPのロードバランシング
コンテンツキャッシュリソースの管理によるサーバーの効率化
Websocketのサポート
セキュリティコントロールのサポート(例:1つのIPアドレスからの接続数の上限設定、リクエストを積極的に呼び出すことによる攻撃の防止)
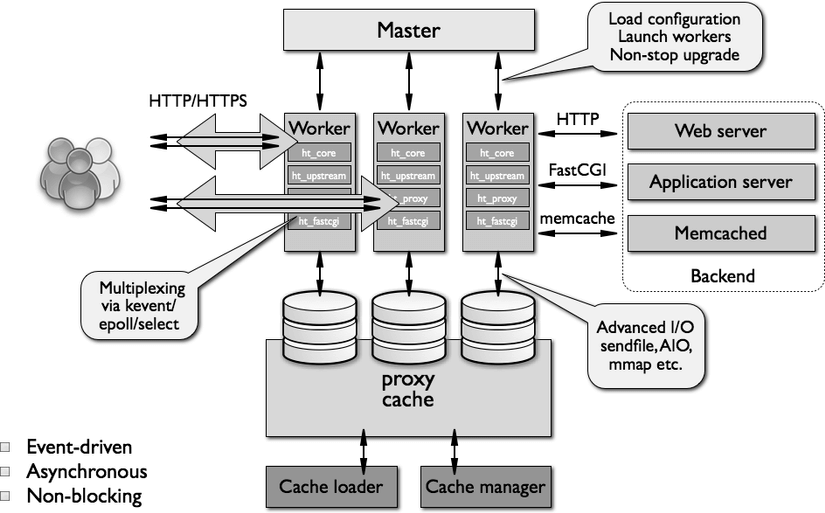
Nginxのアーキテクチャ
NGINXは、非同期アーキテクチャモデル(Asynchronous)とイベント駆動アーキテクチャ(Event-Driven)を採用し、拡張性をもたせています。Nginxは高速であるという利点を活かし、静的コンテンツ(画像、CSS、JS)の利用だけでなく、大規模な同時クエリのナビゲーションを処理するために使用されます。
Nginxのロードバランシング設定例
以下は、Nginxのシンプルなロードバランシング設定の例です:
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://backend;
}
}
}この設定では、backendという名前のサーバーグループを定義し、クライアントからのリクエストをこれらのサーバーに分散させています。
Nginxの負荷分散アルゴリズム
ロードバランサーがリクエストをアプリケーションサーバーにリダイレクトすることを決定するために使用する、4つの基本的な負荷分散アルゴリズムがあります。
ラウンドロビン (デフォルト)
最小の接続数
最短時間
IP ハッシュ(HTTPのみ)
以下は、上記のアルゴリズムの基本的な説明です。
ラウンドロビン
これは最もシンプルなデフォルトのアルゴリズムです。このアルゴリズムでは、Nginxは円周上にあるマシンにのみ、リクエストを1つ1つ送ります。
このアルゴリズムでは、サーバが過負荷であるかどうか、多くのリクエストを受け取っているかは問題ではありません。毎ターン、サーバーはクライアントからのリクエストを処理しなければなりません。
最小の接続数
このアルゴリズムでは、Nginxは最も少ないリクエストを処理しているサーバにリクエストを送ります。これによりシステム内のサーバに偏りがなく、各サーバが同じ数のリクエストに対応できるようになります。
最短時間
このアルゴリズムは、上記の2つのアルゴリズムよりも高度なものになります。つまり、サーバーが処理しているリクエスト数を考慮することに加え、過去に処理されたリクエストの平均処理速度を考慮し、将来どのサーバーがリクエストを受信し処理するかを効果的に調整します。多くのサーバーが存在するシステムでは、すべてのサーバーが同じ構成や同じ処理速度を持つとは限らないからです。
IP ハッシュ
このハッシュアルゴリズムは、クライアントのIPの最初の3オクテットをもとに、どのクライアントをどのサーバに(固定)マップするかを決定するものです。ユーザーのセッションを保持する必要があるアプリケーションに適しています。プール内のサーバーを追加・削除すると、ハッシュ値は再分配されます。追加パラメータのconsistentを使用することで、ハッシュ値の再分配による影響を最小限に抑えることができます。
セッション永続性(Sticky Sessions)
IPハッシュ以外にも、Nginxはセッション永続性を実現するための方法を提供しています。例えば、クッキーを使用してクライアントを特定のサーバーに固定することができます。
upstream backend {
server backend1.example.com;
server backend2.example.com;
sticky cookie srv_id expires=1h domain=.example.com path=/;
}ヘルスチェック
Nginxは定期的にバックエンドサーバーの健全性をチェックし、障害のあるサーバーを自動的に除外します。
upstream backend {
server backend1.example.com max_fails=3 fail_timeout=30s;
server backend2.example.com max_fails=3 fail_timeout=30s;
}HTTPS対応
Nginxを使用してSSL/TLS終端を行うことで、バックエンドサーバーの負荷を軽減し、証明書管理を一元化できます。
server {
listen 443 ssl;
ssl_certificate /path/to/certificate.crt;
ssl_certificate_key /path/to/certificate.key;
location / {
proxy_pass http://backend;
}
}モニタリングとログ
Nginxは詳細なアクセスログとエラーログを提供し、トラフィックパターンや問題の分析に役立ちます。また、Prometheusなどのモニタリングツールと統合することで、 リアルタイムのパフォーマンス監視が可能です。
まとめ
Nginxを使用したロードバランシングは、大規模なWebサイトやアプリケーションの可用性、信頼性、パフォーマンスを向上させる強力なソリューションです。適切に設定することで、トラフィックの増加に柔軟に対応し、ユーザーエクスペリエンスを向上させることができます。
最新のNginx(現在のバージョンは1.27.X)では、さらに高度な機能や最適化が提供されています。常に最新バージョンを使用し、セキュリティアップデートを適用することをお勧めします。
Rabilooは、Nginxを含む最新のテクノロジーを活用したWebアプリケーション開発とシステム最適化のエキスパートです。お客様のビジネスニーズに合わせた効率的なソリューションの提供に豊富な経験を持っています。システムのパフォーマンス向上やスケーラビリティの改善にお悩みの方は、ぜひRabilooにご相談ください。
▶︎React Nativeのパフォーマンスを向上させる基本的な方法
Share